
#44 - Group Rows And Combine Non-Null Values in Each of The Non-Grouping Columns


Problem description & analysis:
In the Excel table below, the 1st column is the category; columns from the 2nd to the 42nd are parallel columns of data items (below only shows some of the columns), where there are two types of values – X and null. Occasionally, there are duplicate values in a column under the same category.
A | B | C | D | E | |
1 | ID | Criteria1 | Criteria2 | Criteria3 | Criteria4 |
2 | FirstValue | X | |||
3 | FirstValue | X | |||
4 | FirstValue | X | |||
5 | FirstValue | X | |||
6 | SecondValue | X | |||
7 | SecondValue | X | |||
8 | SecondValue | X | |||
9 | ThirdValue | X | |||
10 | ThirdValue | X | |||
11 | ThirdValue | X |
Task: Group rows and combine values in each column in each group; only display one of the duplicate values if there are any.
A | B | C | D | E | |
13 | ID | Criteria1 | Criteria2 | Criteria3 | Criteria4 |
14 | FirstValue | X | X | X | X |
15 | SecondValue | X | X | X | |
16 | ThirdValue | X | X |
Solution:
Use SPL XLL to do this:
=spl("=?.group(~1).(g=~,(r1=~1).(g.(~(r1.#)).ifn()))",A2:E11)
As shown in the picture below:
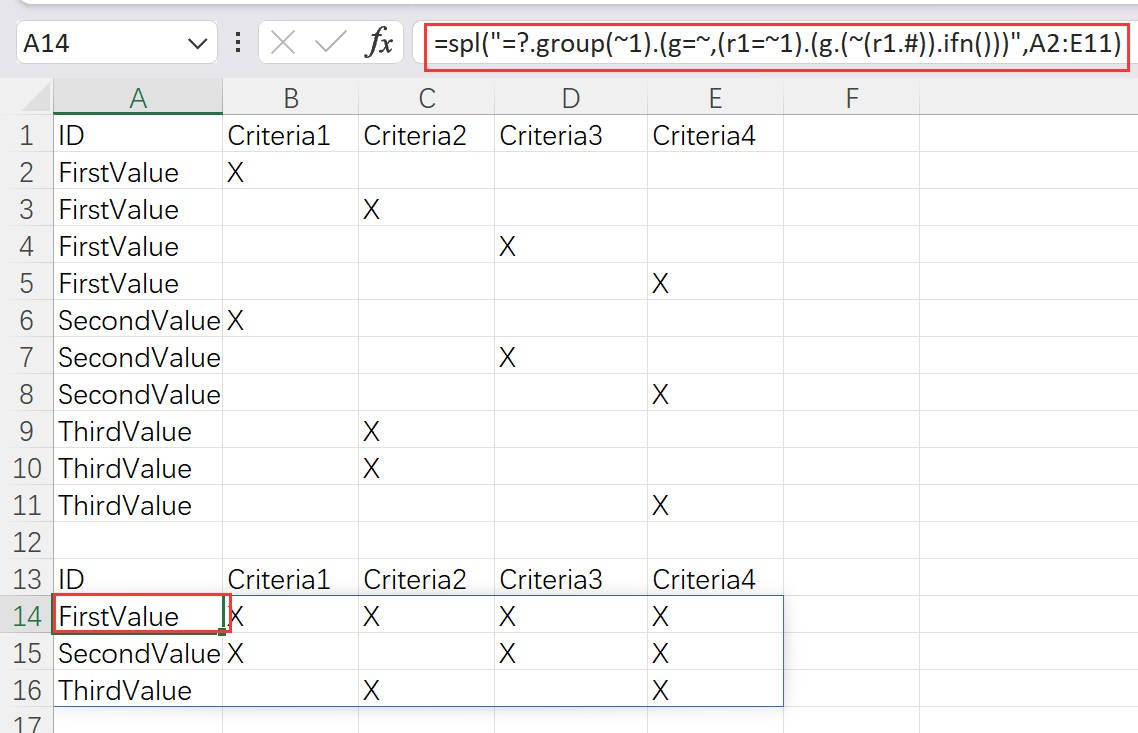
Explanation:
group()function groups data and computes data in each group. ifn() function returns the first non-null member in the sequence, and it returns null if each member of the sequence is null. ~ is the current group; ~1 represents the 1st row of the current group; and # is the ordinal number of the current member.